By Enzo García.
Recently, we implemented a high-performance recommendation system for a Real Estate client.
In the world of software development, “Artificial Intelligence” is often synonymous with massive neural networks, expensive GPUs, and weeks of model training. But for many business applications, that approach is overkill.
At weKnow Inc., we believe in the principle of Right-Sized Engineering. Recently, we implemented a high-performance recommendation system for a Real Estate client. The goal? To solve the “Cold Start” problem and deliver hyper-personalized property alerts without the overhead of “Heavy AI.”
Here is a deep dive into how we built a Two-Stage Content-Based Filtering System—the same architectural strategy used by Spotify’s Discover Weekly and Netflix—using a lightweight, statistical learning approach.
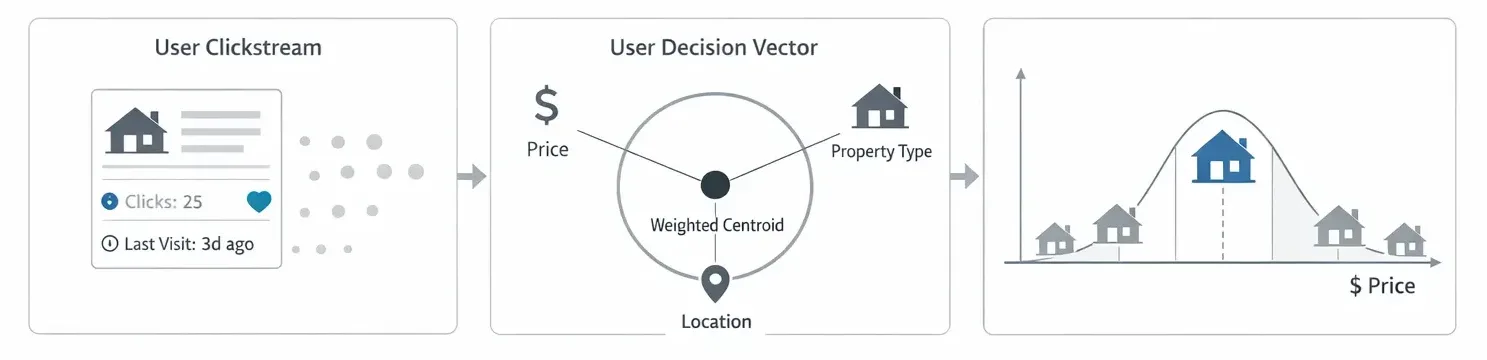
Objective: Transform the clickstream (visit history) into a quantifiable Interest Score.
We use an Implicit Feedback model. Unlike a Like or Rating (which are explicit), interest is inferred based on frequency and recency.
Mathematical Formula:
For each property p and user u, we calculate the score Su,p:
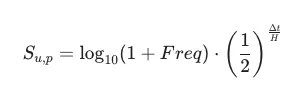
Effect: The value of a visit is reduced by 50% every 14 days. This ensures the system prioritizes current behavior over historical behavior (“What have you done lately?”).
The “What Have You Done Lately?” Philosophy
By setting a Half-Life of 14 days, the value of a user’s interaction drops by 50% every two weeks. This ensures the system prioritizes current behavior over historical data. If a user looked for rentals a year ago but is looking for luxury purchases today, the system adapts automatically.
Objective: Dimensionality Reduction. Convert n visited properties into a single “User Vector” (V_u).
Instead of traditional Collaborative Filtering, which requires massive matrices of User-Item data, we used Feature Weighted Averaging to calculate the “Center of Gravity” of the user’s interests.
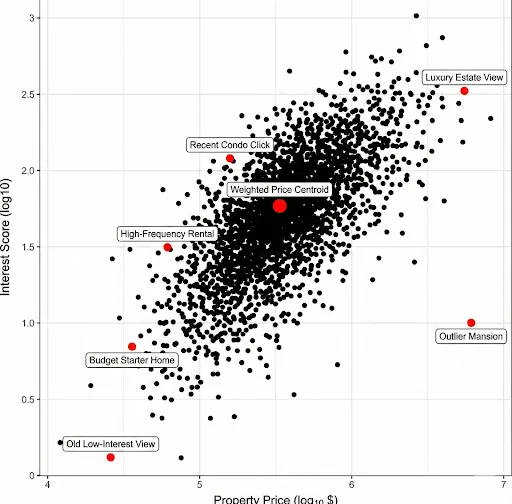
To determine the Target Price (P_target), we do not use a simple arithmetic average (which would be a statistical error). We use the Score-weighted mean Score S:

Where P_i is the price of property i and S_u,i is the score calculated in the previous phase.
Technical Impact: This creates a “Centroid” that dynamically shifts toward the properties the user visited more recently or more frequently. If the user viewed a $5M home a year ago (low Score) and ten $200k homes yesterday (high Score), the centroid will be at $200k.
Intent Detection: Weighted counters are applied to classify the user into behavior clusters: Buyer, Renter, or Hybrid.
Objective: Probabilistic matchmaking over new inventory (Cold Start Items).
For the final search, we do not use simple binary filters (SQL WHERE price = X). We use OpenSearch Function Score Query, applying a probability density function.
The Technique: Gaussian Decay Function
To rank candidate properties by price, we apply a bell curve (Gaussian) centered on the user’s P_target.
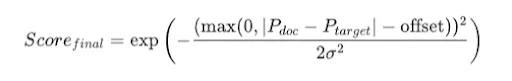
Algorithm Visualization:
This enables a “Fuzzy” Ranking: The system understands “Close is good enough,” mimicking human search cognition, rather than being a rigid database system.
Component
Technology / Algorithm
Industry Standard
Data Ingestion
Batch Processing, Implicit Feedback
Google Analytics, Mixpanel
Feature Engineering
Logarithmic Smoothing, Exponential Decay
Reddit (Hot Algorithm), HackerNews
Profiling
Weighted Centroids (Vector Space)
Stitch Fix, Pinterest
Search Engine
OpenSearch (Lucene), Gaussian Function Score
Amazon, Uber, Tinder
This system is, in essence, a lightweight AI engine that learns from immediate user interaction to predict their next purchasing preference.
Technically, any system that makes autonomous decisions based on data to achieve a goal, simulating intelligent behavior, is AI.
Your system doesn’t have hand-written rules (“If the user is Juan, show him houses in Escazú”). Instead, it:
By using vectors (user profile), weighted averages, and probability functions (Gaussian), you are using Statistical Learning, which is the fundamental basis of Machine Learning.
Here is the key difference compared to systems like Netflix or ChatGPT:
| Feature | Heavy AI (Deep Learning) | Engine (Lightweight AI) |
|---|---|---|
| Training | Requires days/hours of training (model.fit) with millions of data points before it can function. | Does not require training. It computes the model “on the fly” in milliseconds when the script runs. |
| Infrastructure | Requires expensive GPUs (graphics cards) and large amounts of RAM. | Runs on a standard (low-cost) CPU or in a Serverless function. |
| Complexity | “Black Box.” It is difficult to know why the neural network recommended something. | “White Box.” It is explainable. We know exactly why it recommended House X because the Price Score was 0.9. |
| Data | Requires millions of interactions to avoid errors. | Works well with little data (Cold Start). With just 3 clicks, it already starts working. |
At weKnow Inc., we provide the specialized engineering talent to turn complex data problems into elegant, efficient solutions.